

U-Hopper - Big Data Analytics e soluzioni Business Intelligence
Sviluppiamo soluzioni di Big Data Analytics, Business Intelligence ed Intelligenza Artificiale, nel cuore delle Dolomiti.
Scopri tutte le soluzioni

Competenze
Big Data Analytics
Analisi complesse di grandi quantità di dati, indispensabili per estrarre grande valore da una ricca miniera di preziose informazioni.
Visualizzazione dati
Rappresentazione grafica dei dati per monitorare facilmente i KPI e comprendere in modo ottimale i trend. Dopotutto, anche l'occhio vuole la sua parte!
Intelligenza Artificiale e Machine Learning
Algoritmi e modelli matematici per ottimizzare ogni tipologia di processo e favorire il raggiungimento degli obiettivi di business.
Soluzioni
La nostra missione è guidarti alla scoperta del potere e del valore non ancora pienamente sfruttato dei dati aziendali che possiedi, e fornirti gli strumenti adeguati per creare nuove opportunità e un supporto strategico e data-driven al tuo business! Come lo facciamo? Estraendo valore da questi dati tramite soluzioni ad alto contenuto tecnologico!

Analytics & Dashboards
Estrai informazioni rilevanti dai dati aziendali e visualizza i KPI tramite dashboard interattive e personalizzate, facilitandone l'utilizzo in azienda.

Business Intelligence
Ottimizza i processi aziendali per rendere più efficiente il tuo business, grazie all'impiego di modelli avanzati di analisi predittiva e prescrittiva.

Chatbot
Rivoluziona la comunicazione con i tuoi utenti tramite un servizio disponibile h24, 7/7 basato sull’Intelligenza Artificiale e personalizzabile al 100%.






































Academy
L'adozione di nuove soluzioni innovative in azienda necessita di un diffuso percorso di formazione tecnologica. In U-Hopper siamo promotori di questo approccio e attraverso i nostri training e corsi di formazione aziendale vogliamo rendere i temi legati all'analisi dei dati e all'Intelligenza Artificiale accessibili a tutti.
Scopri di piùDatumo: conosci i tuoi clienti, per davvero!
La soluzione che popola il tuo CRM con informazioni accurate e di qualità sui tuoi clienti e sulla quale potrai per costruire le tue strategie di Customer Experience.
Approfondisci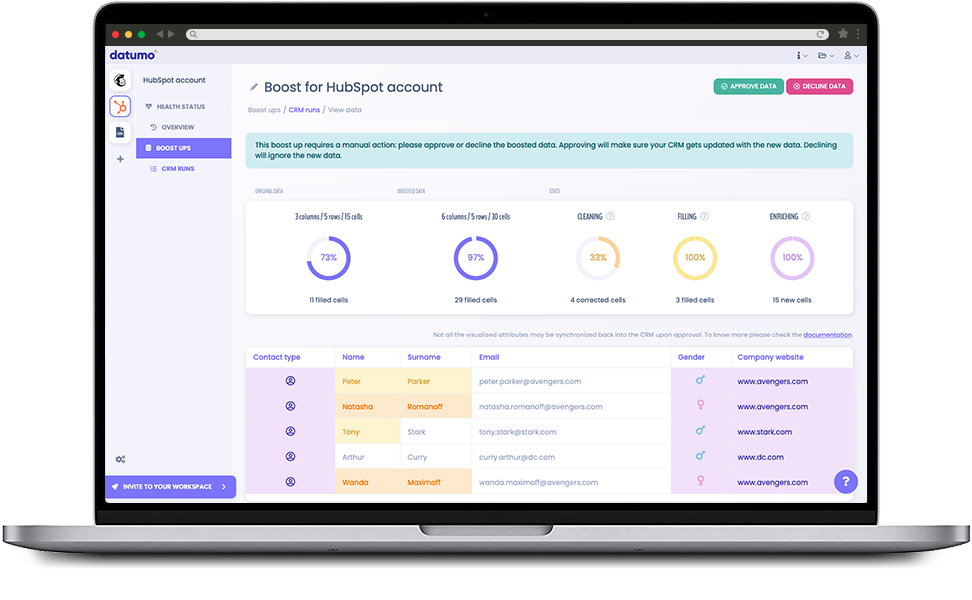
Blog
Tenerti aggiornato sulle nostre ultime novità e sfide per noi è importante.
Ti proponiamo alcuni dei nostri articoli più recenti (e stimolanti!):


