


Collaborations between large companies and small entrepreneurs were an uncommon piece of news, at least until a few years ago. But these times are fortunately over: today, big corporations and start-ups are collaborating more and more often, with the aim of creating solid partnerships that, on the one hand, can bring financial benefits to the latter and, on the other hand, can help the former to innovate and stay competitive on the market. Open Innovation means precisely this, and the proliferation of these virtuous collaborations is also due to the important role played by incubators such as the Business Innovation Centre (BIC) of Trentino Sviluppo .
The experience and the project I would like to talk you about in this article is indeed linked to U-Hopper’s victory of the second edition of the BIC Open Challenge, that is a national contest funding start-ups which respond with an innovative solution to a challenge thrown down by a company established in the BICs of Trentino Sviluppo. This year, the challenge was made by the South Tyrolean company TechnoAlpin , which is leader in the production of snow-making machines and has a headquarter located at the BIC in Trento.
Goal of the challenge was to guide and support TechnoAlpin in a radical change in their data management structure. In particular, we were supposed to help them adopt a Data Lake, while dismissing their Data Warehouse system.
Wait! What exactly are we talking about? Well, Data Warehouse and Data Lake are two totally different approaches to managing and storing data.
The former is a database built for structured data analysis. In other words, the way in which data is stored is defined in advance and is functional to the execution of specific searches (queries) and analyses. Therefore, data needs to be cleaned, enriched and transformed in advance and for the specific, predefined purpose.
A Data Lake, on the other hand, stems from a completely reversed perspective: data is collected and stored with its native format (also called “raw data”), regardless of the final use. Therefore, it is not necessary to define in advance neither schemes and models for its storage, nor its processing. Indeed, this latter phase will only take place (thanks to already configured tools) when data is required to perform a specific analysis.
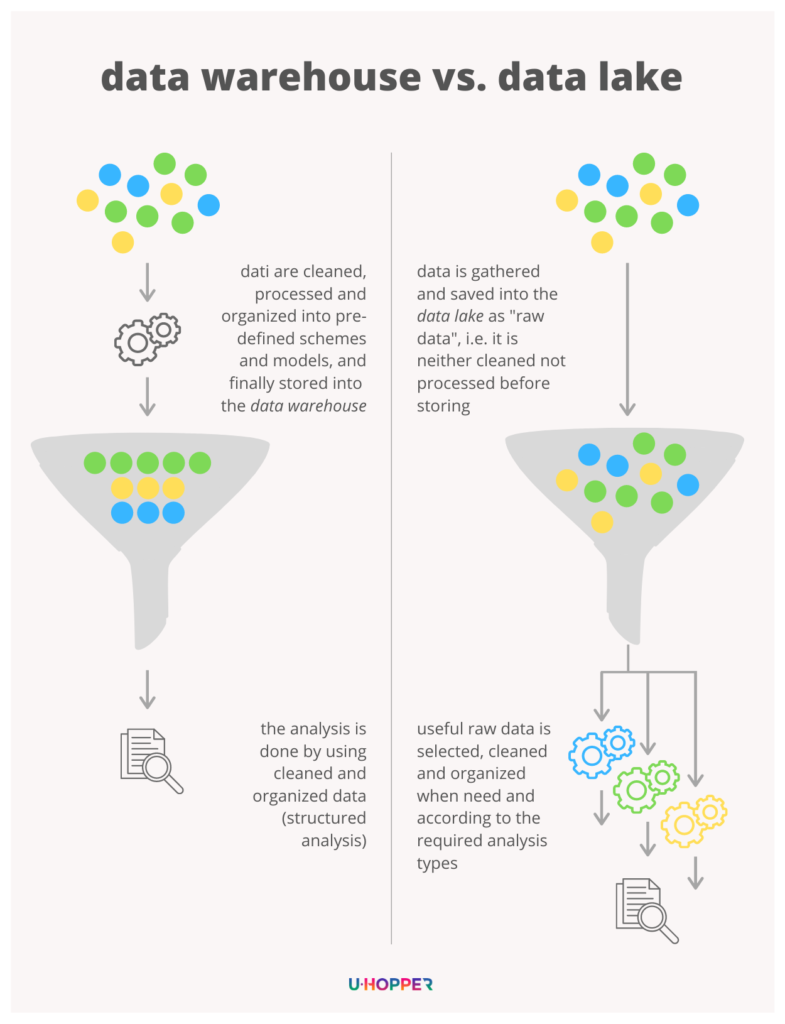 The difference between Data Warehouse and Data Lake (in short)
The difference between Data Warehouse and Data Lake (in short)
The reason behind the use of a Data Lake is its flexibility: raw data can be used for multiple analyses (including those which, at the time of data collection, had not yet been considered) that may require different processing of the same raw data.
In the context of this project, the migration towards a Data Lake approach has therefore allowed us to completely separate the collection process of data from its organization and processing. To do this, we relied on the Azure platform and used both dedicated Microsoft services (Data Factory, Ingestion Pipeline, Vault and Data Bricks – just to name a few) as well as specific tools for data stream analysis and data management (Terraform and Spark).
The result is a more modern and very flexible data collection platform, which is able to collect data of different nature: from that coming from the hundreds of sensors installed on snow-machines, to that data describing weather conditions. At a further stage, the system applies data processing and analysis logics with the aim of preparing reports accessible via dashboards and mobile applications, not only by TechnoAlpin itself but also by its customers.
Furthermore, the flexibility of the Data Lake will allow TechnoAlpin to independently add new logics for future analyses and data processing. In particular, it will be possible to use this data to monitor the performance of snow-machines and develop predictive analyses for the optimization and saving of water and energy resources. An example? By combining the data collected by the sensors with the analysis of meteorological data, it will be possible to schedule the production of snow in the most appropriate time bands.
Ultimately, this project turned out to be an excellent opportunity that allowed us to put our scientific and technological skills into play and, once again, demonstrate the importance of data today: all companies have access to data, and it is a must to know how to manage and use it for creating value and a competitive advantage out of it.